The Vega v1 model proposed by the Wuhan University - JD Trusted Artificial Intelligence Joint Research Center has topped the General Language Understanding Evaluation (GLUE) list, a prestigious global natural language processing list, with an overall average score of 91.3, setting a new world record in this area.
“Vega” makes its stunning debut
The GLUE list, jointly launched by New York University, the University of Washington, Google AI offshoot DeepMind and other institutions, is considered an important metric to measure natural language processing and pre-training techniques.
In the recently released GLUE list, “Vega v1”, a natural language processing model with a very large parameter scale proposed by Wuhan University - JD Trusted Artificial Intelligence Joint Research Center, scored 91.3 and beat Microsoft, Facebook, and Stanford University, clearly demonstrating Vega v1’s leading position in artificial intelligence technology.
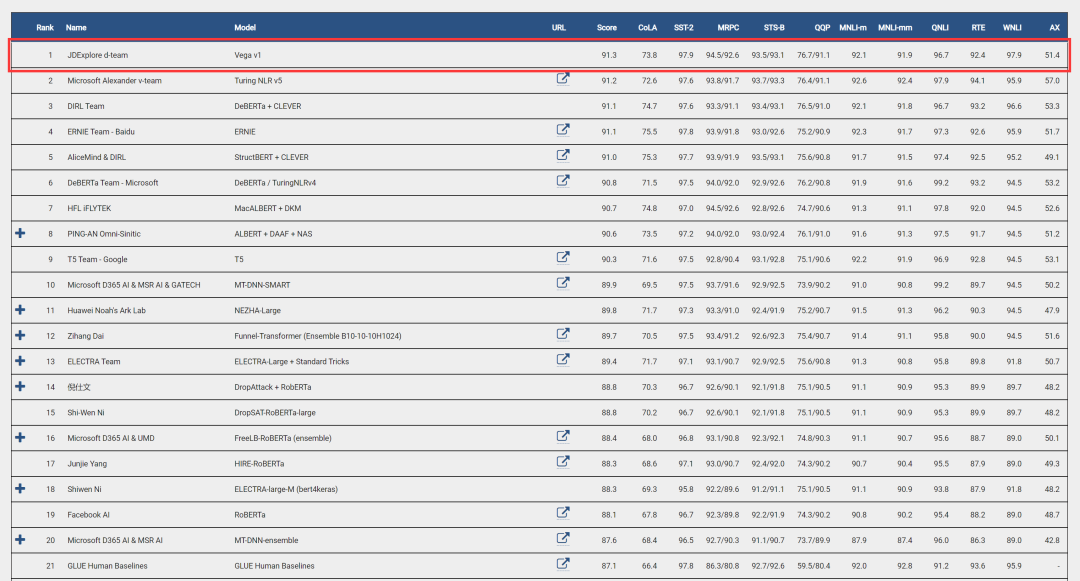
GLUE list ranking chart
This mysterious and romantic name comes from α Lyrae, the super large-scale computing cluster of JD Explore Academy . It is with its support that such large-scale training can be realized. Vega is an alias for α Lyrae, the brightest star in the constellation Lyra. The team wanted the Vega v1 model to be the most special among the pre-training models.

Team members working on the computer
As a general-purpose language model, the Vega v1 model can be applied to a variety of natural language processing tasks and has a wide range of future applications, such as intelligent question and answer functionality, chatbot, grammar correction, and autonomous driving. By adopting model compression, pruning and distillation to lighten Vega v1, a model with smaller parameters can be obtained and deployed in an intelligent terminal, making people’s daily life more convenient.
In addition to the powerful capabilities of the model itself, the team has also adopted many matching and fine-tuning strategies to efficiently update the model’s parameters with a small number of annotated samples for specific downstream natural language processing tasks, effectively improving the accuracy of the Vega v1 model.
It’s a breakthrough to new heights
A lack of generalization is ubiquitous in artificial intelligence. For instance, for each AI task, it is often necessary to train a specific model using a relevant data set. The same specific model that performs well with the current task may not perform as well on other tasks.
To address this challenge and broaden the generality of artificial intelligence, more and more AI employs “generic pre-training model”. Good results can be achieved by training a generic model on a large-scale data set and fine-tuning it for a specific task, effectively solving the problem of insufficient generalizability of models.
The Vega v1 model, as a large-scale pre-training language model, has also achieved good results on a variety of downstream tasks. Compared with other models on the GLUE list, Vega v1 achieves breakthroughs in several pre-training techniques such as an energy-efficient parallelized training framework and data utilization approach, the innovative model architecture with billions of parameters, an improved self-supervised pre-training goal, and allowing the model to learn whole-sentence representations based on different granularities of words, phrases, and short sentences, enabling multi-granular sentence-level representations. These all make the model itself more competitive.
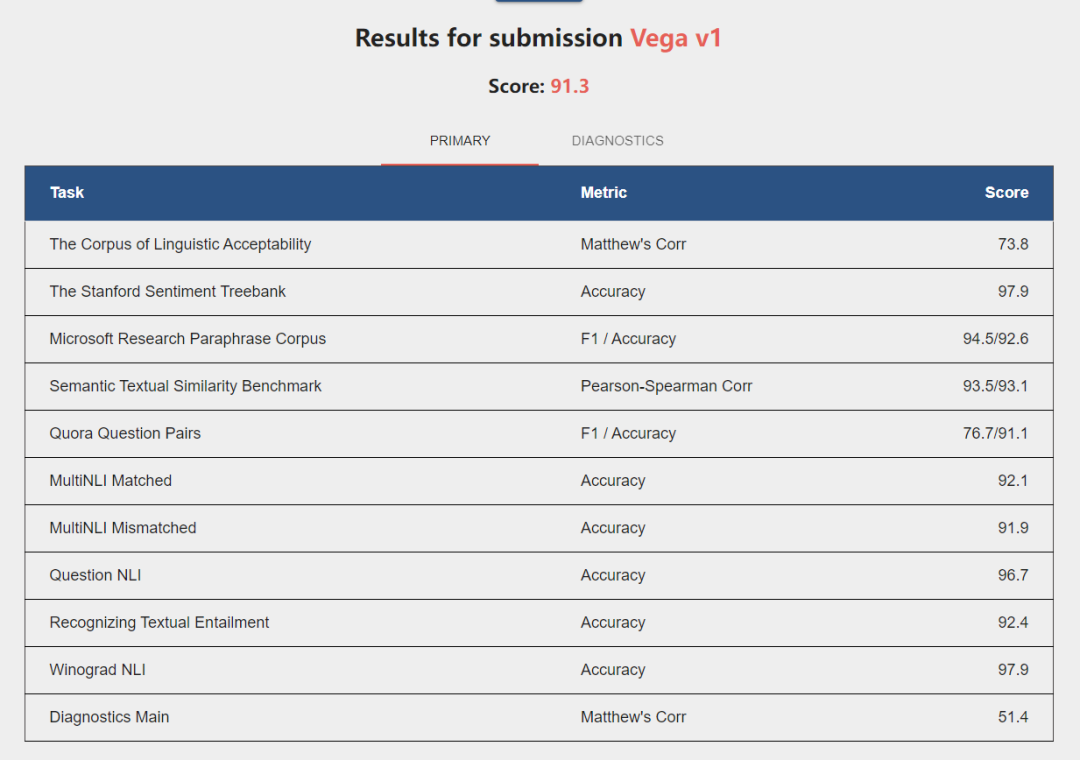
The test results of the Vega v1 model
The GLUE list covers a total of nine major NLP tasks such as natural language inference, semantic textual similarity, question and answer. The human test results for each task are provided at the initial stage of the list’s establishment, representing the level of human intelligence for each task. With the continuous research into pre-training models, such models have been able to outperform human test results on several tasks in GLUE, but sentiment analysis and co-reference resolution have performed more poorly than humans.
The Vega v1 model not only topped the GLUE list with the first overall average score, but also surpassed the human test results on these two challenging tasks for the first time, indicating that it has taken the intelligence of pre-training models to a new level.
In the future, the team will also consider incorporating technologies such as trusted AI to fully upgrade the Vega v1 model by integrating trusted artificial intelligence and other technologies to enhance interpretability, privacy and fairness while constantly improving text understanding capabilities.
The dream makers behind Vega v1
As a research institute jointly established by the WHU Artificial Intelligence Institute, the School of Computer Science and JD, the Wuhan University - JD Trusted Artificial Intelligence Joint Research Center has published dozens of high-level research papers since its establishment in 2021. Additionally, it won first place both in the Video + depth branch of the ICCV-2021 Benchmarking Multi-Target Tracking Competitions and the GLUE Competition, the top test in global natural language processing.

Group photo of the Vega v1 model R&D team
In the process of model training and competition, the team also encountered many difficulties. Due to the lack of experience in large-scale model training, they had to learn many things from scratch; the heavy demand on computing resources for model training poses severe challenges for the effective management of these resources. In the face of these difficulties, the team worked together to analyze the problems, debug codes, and discuss solutions until the early morning. It is these efforts that allow the Vega v1 model to be constantly optimized and improved.
Dr. Zhong Qihuang, the core member of the team, believes that both learning and research require composure and dedication. “Choose a direction, set a time, and the rest is just hard work and persistence. Time will give us the final answer.” In this way, they have been able to overcome difficulties and achieve excellence in the field of artificial intelligence research, just like the star Vega, which shines brightly in the sky.
Like Vega shining in the sky,
The Vega v1 model also yields brilliant results
In its own domain.
On the path of pursuing dreams,
May we all keep shining
In the company of stars.
Rewritten by Zhou Chuangyu
Edited by Su Xinyue, Zou Xiaohan, Sylvia, Xi Bingqing




